All the classification algorithms that we studied in the past, most of them are based on soft-based computation. Soft based computation means as we are giving the prediction from algorithm that point j belongs to which set i ( where i can take any value from 0 to number of sets) but there is category also existed which we called fuzzy-based computation which basically means that the if there is point i and n sets it is not compulsory that it will belong to only one set but there is something called membership function which says that the point can belong to multiple sets. In nutshell, the output is basically the number which indicated the probability of the point to belong to a particular set.
Actually, if you can feel the difference between the simple set and the fuzzy set then you are on the right track otherwise in short note you can say simple set includes the elements which will belong to only one class but the fuzzy sets can contain the element which may belong to multiple sets. This rule is called fuzzy logic.
For e.g. let us take the example of the height of the person you can classify into two classes TALL or SHORT but now think in the terms of the
- Soft based computation: You will say that if the input is greater than some threshold than TALL otherwise short.
- Fuzzy based computation: If the input is very far from the threshold then we are very sure about the output But think like if there is input which is very near to threshold than practically you can not say it as TALL or SHORT then their fuzzy logic comes in the picture which will tell you about the probabilities. So the membership function will look like:

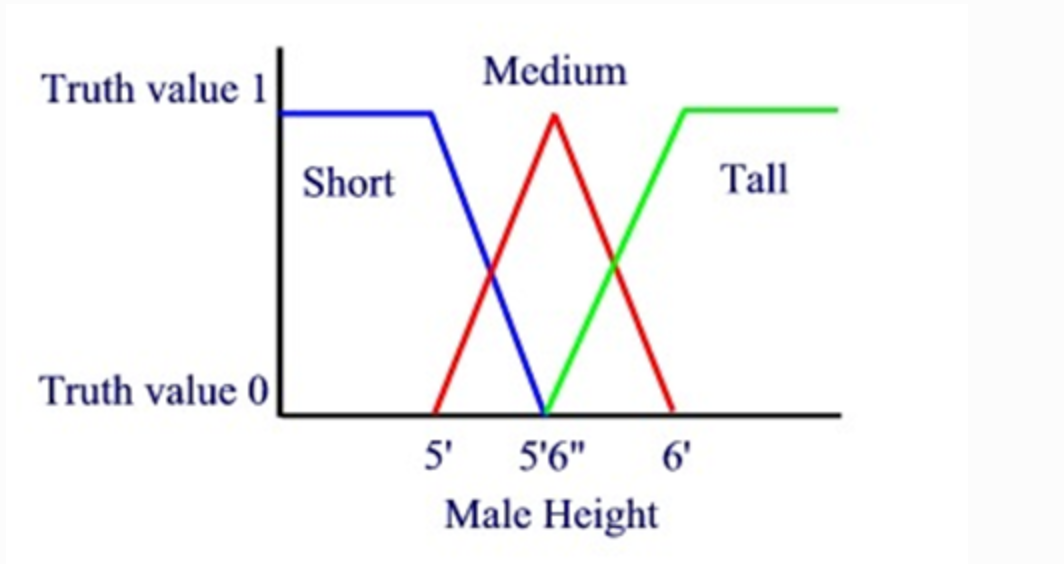
So by now, I think you must be very clear about the fuzzy sets.
Before getting into the FCM algorithm let us understand one more thing called Fuzzy-c partition. The fuzzy-c partition is like to partition the set S into C classes. Where the fuzzy-c partition is defined by tuple (µ, S) where µ represents the matrix of size (i*j) i is the number of points and j is the number of classes. The µ(i,j) represents the membership value of point i for the jth class. There are some rules that each class has to follow to be the class of the fuzzy-c partition.
The rules go likes:
- Every row in the matrix sums should to one.
- Every column in the matrix sums should less than the total number of points in the set.
So as we are done with setting up the base for going fully in the fuzzy c means algorithm. A little bit interesting fact about it is Fuzzy c-means (FCM) clustering was developed by J.C. Dunn in 1973, and improved by J.C. Bezdek in 1981.
Now the algorithm is similar to the k-means but it works differently.
- Choose a number of clusters.
- Assign coefficients randomly to each data point for being in the clusters.
- Repeat until the algorithm has converged.
- Compute the centroid for each cluster.
So the fuzzy-c means algorithm will not overfit the data for clustering like the k-means algorithm it will mark the data point to multiple clusters instead of the one cluster which will be more helpful than giving the point to the one cluster.
Why we should use Fuzzy C instead of k means:

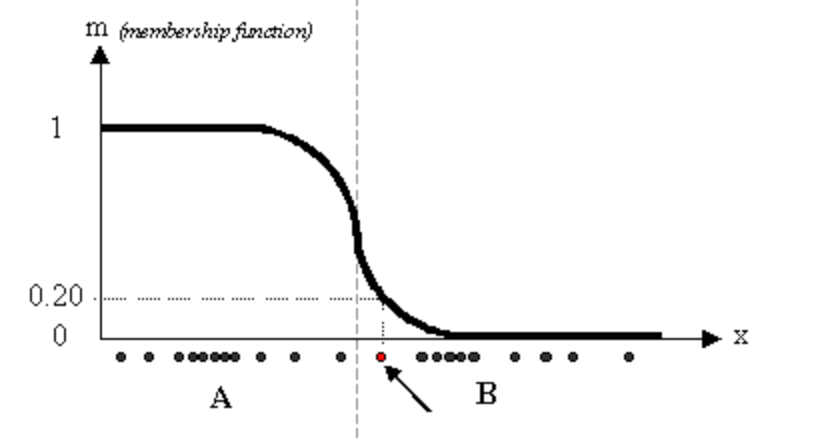
The main reason it works equal to the k means algorithm but the only thing that differentiates it from the others is that it will be the best to differentiate the point which can be assigned to multiple clusters.
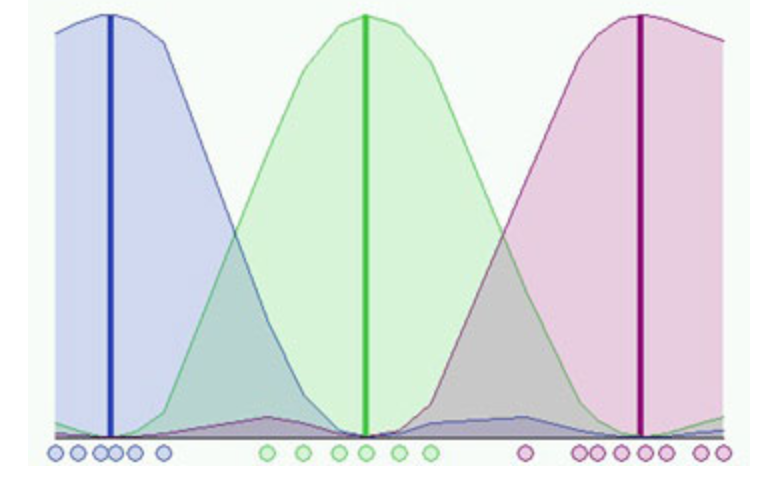
I hope you guys learned from this and if not, please feel free to ask questions.
Thanks.
Comments
Post a Comment