The worst performance of the ML( Machine Learning ) Models is due to the Overfitting and Underfitting largely. As in the past, we discovered that the generalization is the idea that every model should do but the overfitting and underfitting will go along with them so we generally have to more aware that the model should not do the overfitting and underfitting. A vital factor in determining the objective function from the training data is how well the model generalizes to new data. Generalization is important because the data we receive is only a sample, it is incomplete and noisy.
Overfitting:-


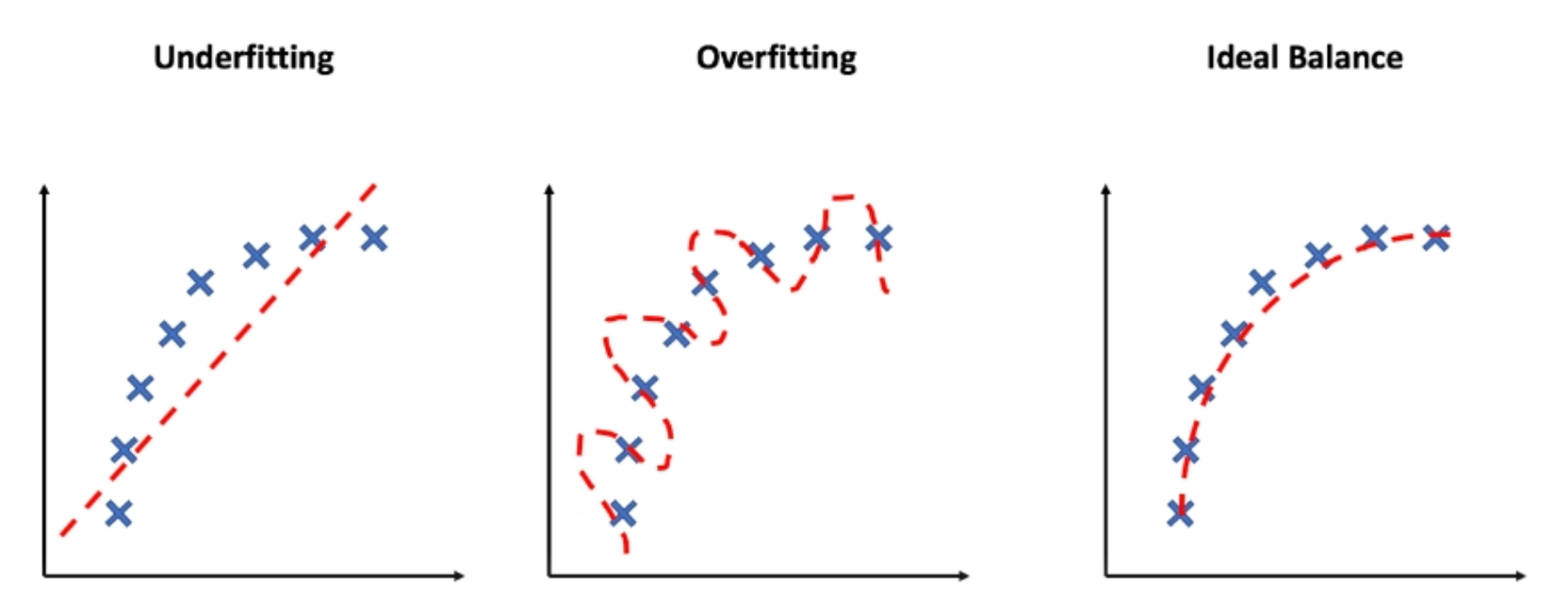
Overfitting is the bug in the ML which means that the model trains itself very much on the training data set.
Overfitting happens when a model learns the detail and noise in the training data to the extent that it negatively influences the appearance of the model on brand-new data. This actually gives us the idea that the noise in the training data set is picked up and learned as ideas by the model. The dilemma is that these ideas do not apply to the test data set and negatively impact the model’s ability to generalize.
Overfitting is more likely with nonparametric and nonlinear models that have more flexibility when learning a target function. There are many models that can face this problem for e.g. Random forest.
For example, decision trees are a nonparametric machine learning algorithm that is very flexible and is subject to overfitting training data. This problem can be approached by clipping a tree after it has learned in order to remove some of the detail it has picked up. This problem can be seen many times in the decision trees.
Underfitting in Machine Learning


Overfitting is the bug in the ML which means that the model can’t generalize to the new data and can not fit the training data set also.
An underfit machine learning model is not the best model and will be clear as it will have poor performance on the training data and will also perform worst on the test data set.
Underfitting is often not discussed as it is easy to detect given a good performance metric. The solution is to move on and try alternate machine learning algorithms. Nevertheless, it does provide a good contrast to the problem of overfitting. So my only suggestion for you is to try some new model and it will help many times.
As we saw the defination of both underfitting and overfitting and we are sure that the underfit is not that big threat it is solvable by just trying the new model but the overfit is major bug in the machine learning models so to resolve this bug there are some few tips from my side to yours.
Overfitting — Solution for this bug


Overfitting is such a problem because the evaluation of machine learning algorithms on training data is different from the evaluation of the data set that we actually want the model to perform well.
There are two powerful procedures that one can use when evaluating machine learning algorithms to smash overfitting:
- Resampling technique.
- Validation dataset.
The common hot resampling technique is k-fold cross-validation. It allows us to train and test your model k-times on different subsets of training data and build up an estimate of the performance of a machine learning model on unseen data.
A validation dataset is simply a subset of your training data that you hold back from your machine learning algorithms until the very end of your project. After you have selected and tuned your machine learning algorithms on your training dataset you can evaluate the learned models on the validation dataset to get a final objective idea of how the models might perform on unseen data.
I hope this will help you in understanding the biggest bug in the machine learning model and also help you in to smash it. #bug_smash
Comments
Post a Comment