As we previously examine the KNN that how it works and how to select the K for better outcomes and no overfitting. In this article, we will be going to code the python version for KNN and we will find the most immeasurable value of K to use for better outcomes.
Find the below code with explanation:
Import the necessary libraries which we will need for the future.


Now load the dataset from the local and find how rows look in it.

To download the dataset please refer to the following link.
Now select all the features and the target_class from the set and divide the set into test and train by 33% and 67%.


Now for a range values of K fit on the training dataset and then test on the test dataset and find the accuracy and then store it into some array.


Now plot the K-values with their corresponding accuracy and see which value is best.

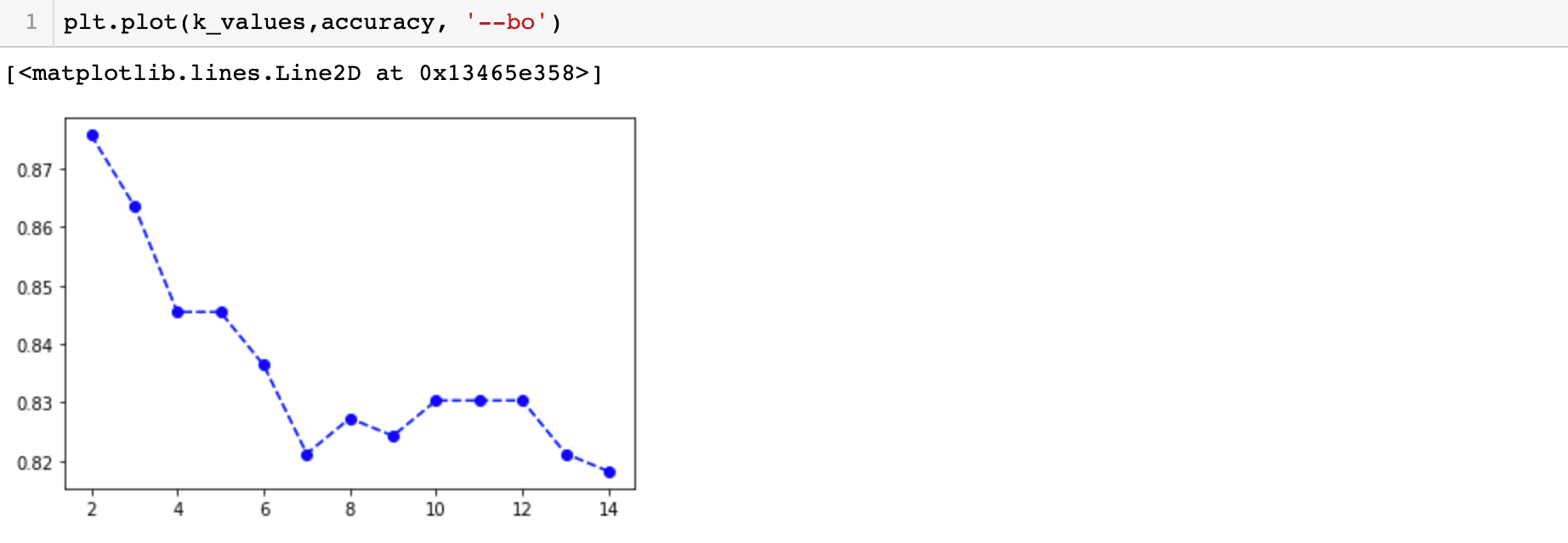
Now we have our model and we can predict any given unknown value with more accuracy because now we know the best value of k.
Thanks for browsing my pattern, and I hope it benefits you in theory and in practice!!!!
Comments
Post a Comment