KNN is a powerful classifier and a regressor. yes, you got it right we can do both regression or classification by this algorithm. For its implementation in python please visit this link.


What is KNN and how it works:
Let’s head by setting some definitions and notations. We will take x to denote a feature and y to denote the target.
KNN falls in the supervised learning algorithms. This means that we have a dataset with labels training measurements (x,y) and would want to find the link between x and y. Our goal is to discover a function h:X→Y so that having an unknown observation x, h(x) can positively predict the identical output y.
Working
First, we will talk about the working of the KNN classification algorithm. In the classification problem, the K-nearest neighbor algorithm essentially said that for a given value of K algorithm will find the K nearest neighbor of unseen data point and then it will assign the class to unseen data point by having the class which has the highest number of data points out of all classes of K neighbors.
For distance metrics, we will use the Euclidean metric.


Finally, the input x gets assigned to the class with the largest probability.
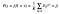

For Regression the technique will be the same, instead of the classes of the neighbors we will take the value of the target and to find the target value for the unseen datapoint by taking an average, mean or any suitable function you want.
Ideal Value for K
Now most probably, you are wondering how to decide the value for variable K and how it will affect your classifier. Well, like most machine learning algorithms, the K in KNN is a hyperparameter that you, as a data scientist, must decide in place to get the most suitable fit for the data set.
When K is small, we are holding the region of a given prediction and pushing our classifier to be “more blind” to the overall distribution. A small value for K provides the most adjustable fit, which will have low bias but high variance. Graphically, our decision boundary will be more irregular. On the other hand, a higher K averages more voters in each prediction and hence is more flexible to outliers. Larger values of K will have smoother decision boundaries which means lower variance but increased bias.


Improvements
- An easy and mild approach to change skewed class distributions is by implementing weighted voting.
- Changing the distance metric (i.e. Hamming distance for text classification)
- Dimensionality reduction techniques like PCA should be executed prior to applying KNN and help make the distance metric more meaningful.
Thanks for browsing my pattern, and I hope it benefits you in theory and in practice!!!!
thromadfran_pu1978 Sima Lenz https://wakelet.com/wake/y_jYcdr-IIJ9JH0wqUB06
ReplyDeleterecnalime
Vfecralur-ri-1993 Dave Hundley
ReplyDeleteAwesome
growlaytouchsders