
Logistic Regression:
Logistic regression is a classification algorithm used to determine the values for the discrete classes. Unlike the linear regression which usually outputs the continuous value, the logistic regression uses sigmoid function and it will output the probability which will then mapped to the two or more classes.
There can be two types of logistic regression possible which are:
- Binary: (having two classes)
- Multi-variable: (having more than two)
First of all, let us understand the binary logistic regression and then it will be too easy to grasp what is multi-variable logistic regression.
Binary Logistic Regression:
As notified that name binary, so we will trade with the two classes primarily, we will just determine the probabilities and based upon some rule we will determine which class it belongs to mostly we will do like if p(x) > 0.5 then 1st class else 0th class. So we will decide the class like this simply. For predicting the probability we will use sigmoid function in the logistic regression which looks like
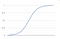

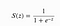
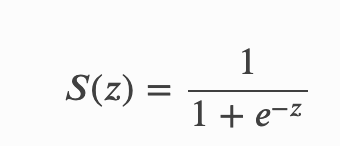
- s(z) = output between 0 and 1 (probability estimate)
- z = input to the function (your algorithm’s prediction e.g. MX + b)
- e = base of natural log
Multiclass Logistic regression:
Instead of only two classes, we will extend our boundary so that now we have n classes from 0 to n-1 Essentially we run binary classification multiple times, once for each class.
Method:
- Divide the problem into n binary classification problems
- For each class…
- Predict the probability.
- prediction = <math>max(probability of the classes
For each sub-problem, we select one class and lump all the others into a second class. Then we take the class with the highest predicted value.
Future Learning:
- Tolles, Juliana; Meurer, William J (2016). “Logistic Regression Relating Patient Characteristics to Outcomes”.
- Walker, SH; Duncan, DB (1967). “Estimation of the probability of an event as a function of several independent variables”.
Comments
Post a Comment